If an alignment between two ontologies explicitly specifies correspondences between similar entities from these ontologies, then it also specifies which resources are likely to be interlinked. From this, the question is whether data interlinking can be seen as an extension of the ontology matching process and if it makes sense to merge data interlinking and ontology matching tools.
Although, ontology matching and data interlinking can be similar at a certain level (they both relate formal entities), there are important differences as displayed by the the previous framework resulting from the analysis of existing systems. Indeed, one acts at the schema level and the other at the instance level.
These differences are reflected in the types of specification involved in these processes:
| process | result | |
| instance | linker specification | linkset |
| class | matcher | alignment |
By clearly establishing these differences, we obtain a natural partitioning between data links, linking specifications and ontology alignments and the languages for expressing them:
We first present an expressive language for ontology alignments that can be exploited by data interlinking systems. Then we show how it could be used fruitfully in data interlinking.
EDOAL (Expressive Declarative Ontology Alignment Language) is the new name of the OMWG mapping language for expressing ontology alignment [euzenat:2007] that has been available through the Alignment API since version 3.1. This language is an extension of the Alignment format [euzenat:2004] that can be generated by most matchers. Its main purpose is to offer more expressiveness in the way alignments are expressed. It presents the advantage to be declarative and also to specify transformations like those needed in order to construct links between resources.
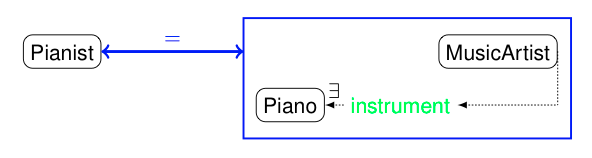
A first advantage of the expressiveness of EDOAL is the possibility to express correspondences between non named entities. For instance, a simple assertion such as ``a pianist is a musician who plays piano'', can be expressed by (also in the following figure):
:dbp-mo a align:Alignment;
align:onto1 <http://dbpedia.org/ontology/>;
align:onto2 <http://www.musicontology.com/>;
align:map [ :map1 a align:Cell;
align:entity1 dbp:Pianist;
align:entity2 [ a edoal:Class;
edoal:and mo:MusicArtist;
edoal:and [ a edoal:PropertyValueConstraint;
edoal:property mo:instrument;
edoal:value mo:Piano.
].
];
align:relation align:equivalent;
].
This can help restricting the search space of data interlinking tools far beyond what they currently do (named classes).
In addition, in EDOAL, it is possible to express that two classes are equivalent, and that their instances are equivalent modulo a transformation. This can be used for covering, without further information, the URI correspondence case of the framework. For instance, the following figure shows an EDOAL correspondence using regular expression transformations for identifying musician instances between two data sets with different conventions.
Of course, this can only work when there exists such correspondences, i.e., an exact method for generating links. Most of the time, data interlinking systems still need to use heuristics to find links between entities. This can be provided by the simple Alignment format, but EDOAL can do more by indicating where to look for to establish the correspondence.
In particular, EDOAL allows for expressing contextual relations between elements. For instance, the typical example in Silk documentation is the linking of DBpedia cities and geoname P(laces) through comparing their names and populations. Expressing this with the simple alignment:
:dbp-geo a align:Alignment;
align:onto1 <http://dbpedia.org/ontology/>;
align:onto2 <http://www.geonames.org/ontology#>;
align:map [ :map1 a align:Cell;
align:entity1 dbpedia:City;
align:entity2 gn:P;
align:relation align:subsumedBy.
];
align:map [ :map2 a align:Cell;
align:entity1 dbpedia:populationTotal;
align:entity2 gn:population;
align:relation align:equivalent.
];
align:map [ :map3 a align:Cell;
align:entity1 rdfs:label;
align:entity2 gn:name;
align:relation align:equivalent.
].
does not express the expected meaning because, of course, rdfs:label is not equivalent to gn:name.
One could consider expressing that gn:name is more specific than rdfs:label.
This is correct but still not precise enough.
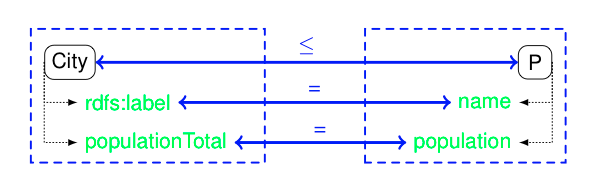
The intended meaning is that, in the context of dbpdia:City and gn:P, these two properties are equivalent.
This is what EDOAL can express through the schema of the following figure corresponding to the following alignment:
:dbp-geo a align:Alignment;
align:onto1 <http://dbpedia.org/ontology/>;
align:onto2 &lp;http://www.geonames.org/ontology#>;
align:map [ :map1 a align:Cell;
align:entity1 dbpedia:City;
align:entity2 gn:P;
align:relation align:subsumedBy.
];
align:map [ :map2 a align:Cell;
align:entity1 [ a align:Property;
edoal:and dbpedia:populationTotal.
edoal:and [ a edoal:PropertyDomainRestriction;
edoal:domain dbpedia:City. ];
align:entity2 [ a align:Property;
edoal:and gn:population;
edoal:and [ a edoal:PropertyDomainRestriction;
edoal:domain gn:P. ];
align:relation align:equivalent.
];
align:map [ :map2 a align:Cell;
align:entity1 [ a align:Property;
edoal:and rdfs:label.
edoal:and [ a edoal:PropertyDomainRestriction;
edoal:domain dbpedia:City. ];
align:entity2 [ a align:Property;
edoal:and gn:name;
edoal:and [ a edoal:PropertyDomainRestriction;
edoal:domain gn:P. ];
align:relation align:equivalent.
].
Instance alignment, as studied in the context of ontology matching [euzenat:2007b], slightly differs from matching resources between web data sets. When in instance matching one ontology is generally attached to one knowledge base, many web data sets can be described according to the same ontology. The problem is in this case simplified, as the ontology will guide the matching process to consider only instances of the same class. When two data sets are described according to heterogeneous ontologies, aligning the ontologies before interlinking the data sets will facilitate the matching process. Another possibility is that the ontology is not explicitly given and must then be reconstructed by the matching system.
Even if such an alignment would provide information to data interlinking tools, this is still not sufficient. Of course, it tells which properties should be equivalent and thus can be used for identifying entities. But it does not tell how to take them into account. So, this alignement would be sufficient to link entities if the values of rdfs:label were exactly the same as those of gn:name and the values of populationTotal were exactly the same as those of population, but not otherwise.
EDOAL provides more features for transforming this information. This could be helpful but the problem is deeper: data interlinking is a decision problem rather that just a transformation. It is the role of the data linking specification to tell when a particular dbpedia:City and a gn:P should be considered the same. This is why we propose to use data interlinking specifications together with alignments.
Apart from Knofuss, interlinking tools do not provide the possibility to use an ontology alignment. Knofuss still needs to specify queries on both data sets from which results equivalent resources will be identified.
Indeed, using an explicit alignment, provided that it is expressive enough, can serve two functions:
Below is the Silk-LSL [bizer:2009] specification to interlink cities in the two data sets DBpedia and Geonames:
<Silk>
<Prefix id="rdfs" namespace=
"http://www.w3.org/2000/01/rdf-schema#" />
<Prefix id="dbpedia" namespace=
"http://dbpedia.org/ontology/" />
<Prefix id="gn" namespace=
"http://www.geonames.org/ontology#" />
<DataSource id="dbpedia">
<EndpointURI>http://demo_sparql_server1/sparql
</EndpointURI>
<Graph>http://dbpedia.org</Graph>
</DataSource>
<DataSource id="geonames">
<EndpointURI>http://demo_sparql_server2/sparql
</EndpointURI>
<Graph>http://sws.geonames.org/</Graph>
</DataSource>
<Interlink id="cities">
<LinkType>owl:sameAs</LinkType>
<SourceDataset dataSource="dbpedia" var="a">
<RestrictTo>
?a rdf:type dbpedia:City
</RestrictTo>
</SourceDataset>
<TargetDataset dataSource="geonames" var="b">
<RestrictTo>
?b rdf:type gn:P
</RestrictTo>
</TargetDataset>
<LinkCondition>
<AVG>
<Compare metric="jaroSimilarity">
<Param name="str1" path="?a/rdfs:label" />
<Param name="str2" path="?b/gn:name" />
</Compare>
<Compare metric="numSimilarity">
<Param name="num1"
path="?a/dbpedia:populationTotal" />
<Param name="num2" path="?b/gn:population" />
</Compare>
</AVG>
</LinkCondition>
<Thresholds accept="0.9" verify="0.7" />
<Output acceptedLinks="accepted_links.n3"
verifyLinks="verify_links.n3"
mode="truncate" />
</Interlink>
</Silk>
This specification fulfills two roles:
It could be possible to refer to an external alignment between the two underlying ontologies instead of specifying it in the linking specification. This approach would present obvious reuse advantages when other data sets requiring the same alignment, i.e., using the same ontologies, need to be interlinked.
Given that the alignment is available, it is possible to simplify the Silk specification and refer to the alignment, by introducing three types of information: which alignments to use (UseAlignment), entities of which correspondences must be linked (LinkCell) and which matched properties can be compared for identifying entities (CellParam).
<UseAlignment rdf:resource="#dbp-geo" />
<Interlink id="cities">
<LinkType>owl:sameAs</LinkType>
<LinkCell rdf:resource="#map1" />
<LinkCondition>
<AVG>
<Compare metric="jaroSimilarity">
<CellParam rdf:resource="#map2" />
</Compare>
<Compare metric="numSimilarity">
<CellParam rdf:resource="#map3" />
</Compare>
</AVG>
</LinkCondition>
<Thresholds accept="0.9" verify="0.7" />
<Output acceptedLinks="accepted_links.n3"
verifyLinks="verify_links.n3"
mode="truncate" />
</Interlink>
The specifics of the data interlinking task remain in this specification: how to compare values, how to aggregate their results and when to issue the link or not.
In fact, the symbiosis between the alignment and the linking specification can be rendered even more automatic, e.g., by defining default rules for comparing values of a given type, default rules for aggregating metrics, and default threshold rules. However, it is also useful that the linking specification designer can keep control on what the interlinking tool does and, even if a correspondence is not in an alignment, be able to define it.
One may want to go further. Indeed, data interlinking is primarily a matter of identification of entities. Hence, it could be worth specifying the set of properties that uniquely identify an entity. In databases, this is what is called a key. Incidentally, the OWL 2 ontology language has introduced keys [motik2009a].
In the context of data interlinking, one could imagine that given the key of a particular class (given by an ontology) and the corresponding properties in another class (given by an alignment), the data interlinking tool can identify the corresponding entities through a comparison measure (given by a linking specification).
Unfortunately, what could be a key in the context of a particular data set (like the employee number) may not be a key anymore in a wider context. If this idea of simplifying the linking specifications by using keys seems interesting, it cannot be used so directly.
François Scharffe and Jérôme Euzenat